Ponto Cego do Mercado
Quando a linguagem limita


TLDR: A obsessão da Inteligência Artificial por “tokens” e pela linguagem verbal pode estar limitando seu potencial, criando vieses e falhando em representar a complexidade do mundo. O preço dessa abordagem rígida é alto, mas uma transição fundamental já está em curso, prometendo uma era de saltos sem precedentes em direção a modelos mais eficientes e verdadeiramente globais.
Quando o assunto é o desenvolvimento da Inteligência Artificial, algumas entrevistas recentes me marcaram. Uma, em particular, foi a de Ilya Sutskever (na época, Chief Scientist da Open AI) para o podcast de Dwarkesh Patel. Nela, ele fez uma afirmação ousada: a de que os modelos baseados em “predição dos próximos tokens” seriam suficientes para alcançarmos uma Inteligência Artificial Geral, a famigerada AGI.
Naquele momento, sua fala era uma defesa clara da estratégia de escala dos modelos existentes. Afinal, era uma abordagem que havia funcionado muito bem até então.

Fonte: Youtube
Se você não faz ideia do que é um “token”, fique tranquilo. A promessa é que, até o final deste artigo, o conceito ficará mais claro. O importante agora é saber que existe uma relação umbilical entre tokens e a linguagem verbal.
Aliás, é a própria linguagem que, nos últimos três anos, se tornou o alicerce da maioria dos avanços em IA — não à toa, os modelos do momento são os LLMs (Large Language Models). E essa dominância da linguagem na máquina é o gancho perfeito para refletirmos sobre o papel dela no desenvolvimento da nossa própria inteligência.
Se você, leitor ou leitora, tem um filho ou já acompanhou de perto o desenvolvimento de uma criança, sabe de algo fundamental: muito antes de dominar a linguagem verbal, ela já demonstra uma clara capacidade cognitiva e racional. Notamos isso na curiosidade, na atenção, no reconhecimento de rostos e objetos, na memória e até na compreensão social e emocional.
Tudo isso acontece muito antes que a fala se estruture por completo — o que ocorre normalmente lá pelos 4 anos (a menos, claro, que estejamos falando da ‘menininha do Itaú’).

Fonte: Google Imagens
É claro, a importância da linguagem verbal no nosso desenvolvimento cognitivo posterior é inegável — ela simplifica o mundo para que possamos fazer coisas mais complexas.
Só que essa simplificação tem um preço e nos limita de formas que nem fazemos ideia. Pense na palavra ‘saudade’, que não tem tradução direta em tantas línguas, ou nas múltiplas representações do amor no grego antigo. No momento em que damos nomes às coisas, ‘fatiamos’ a realidade contínua em caixas discretas e, nesse processo, perdemos parte da nossa sensibilidade inicial.
O que vem primeiro? As regras da linguagem verbal ou a nossa necessidade de nos expressarmos? Quando li “Preconceito Linguístico”, de Marcos Bagno, ficou evidente que a linguagem é refém da necessidade, que ela é viva, dinâmica. Enquanto as regras tentam “congelar” a língua, o uso cotidiano a força a evoluir.

Fonte: Google Imagens
Aqui podemos fazer um paralelo com o desenvolvimento atual da IA e os precursores das LLMs: os modelos de processamento de linguagem natural – NLPs. Desde os primórdios da IA, lá na década de 50, a discussão sobre processamento de linguagem sempre foi quente, envolvendo tanto filosofia, como linguística e matemática. Como ensinar as máquinas a compreender nossa linguagem?
Vários pesquisadores se debruçaram no tema, sem haver consenso. Alguns imaginavam ser necessário identificar uma “Gramática Universal”, que separasse cada elemento de uma língua nos seus diversos componentes, com suas respectivas funções. Essa seria a base para a compreensão de toda linguagem verbal. Só que isso se demonstrou limitado e incapaz de capturar nuances mais complexas no mundo real.

Fonte: Google Imagens
Quando vieram os invernos da IA, o assunto esfriou e as discussões sobre linguagem ficaram restritas aos círculos acadêmicos dos linguistas. Porém, à medida que surgiam novos avanços computacionais, os estudos de processamento de linguagem natural foram voltando à cena e novas abordagens foram (re)surgindo: uma delas tinha a ver com a distribuição estatística dos elementos básicos da linguagem, ou tokens.
A forma mais simples de ‘tokenizar’ um texto é considerar que cada caractere é um token. Isso, porém, gera uma estrutura tão simplista que os modelos se tornam incapazes de criar qualquer tipo de abstração ou representação simbólica.
O passo seguinte, naturalmente, é usar as palavras como token. Essa abordagem funciona até certo ponto, mas o vocabulário se torna extremamente redundante — pense em ‘correr’, ‘correu’ e ‘correndo’ como três tokens distintos e sem relação: palavras similares são tratadas como coisas totalmente diferentes.
É aí que entram em cena os tokenizadores atuais (como os subwords). Eles geram representações muito mais eficientes ao encontrar o ponto de equilíbrio perfeito: reduzem as redundâncias do modelo por palavra e, ao mesmo tempo, mantêm a flexibilidade do modelo por caractere.
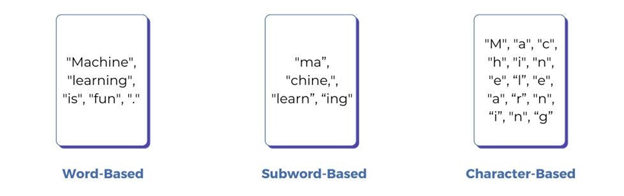
Fonte: artigo no Medium “What is Tokenization in NLP? Everything You Need to Understand”, por Eastgate Software
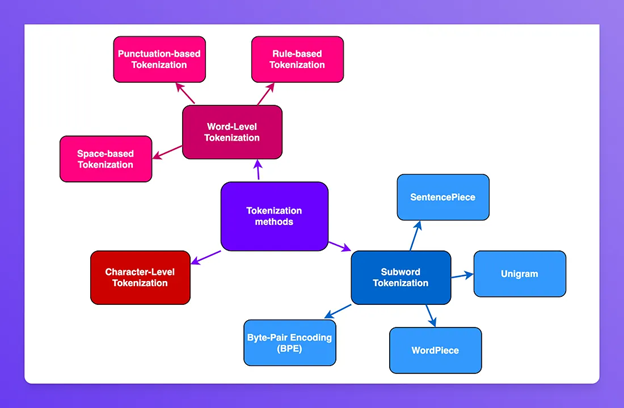
Fonte: artigo no Medium “Two minutes NLP — A Taxonomy of Tokenization Methods”, por Fabio Chiusano
Mas e quando a representação da língua é fundamentalmente diferente? E se não houver um alfabeto, ou silabário — um conjunto de elementos básicos que se combinam para formar palavras?
Como representar o mandarim, por exemplo?

É exatamente aqui que a contribuição multicultural se torna indispensável para o desenvolvimento da Inteligência Artificial. E não, não mencionei o mandarim à toa: hoje, a China é uma das maiores forças motrizes no avanço global da IA.
Para ser direto: qualquer projeção sobre o futuro da tecnologia que não coloque a China como uma peça central está bastante desatualizada. E esse protagonismo vai muito além do clichê do “mercado consumidor gigante”. O país hoje tem uma reserva de talentos incomparável: é o maior formador de profissionais em STEM do mundo e, com um cenário de tecnologia local agora maduro e vibrante, o país consegue reter e atrair mentes brilhantes que, antes, teriam como destino certo o Ocidente, especialmente os Estados Unidos.
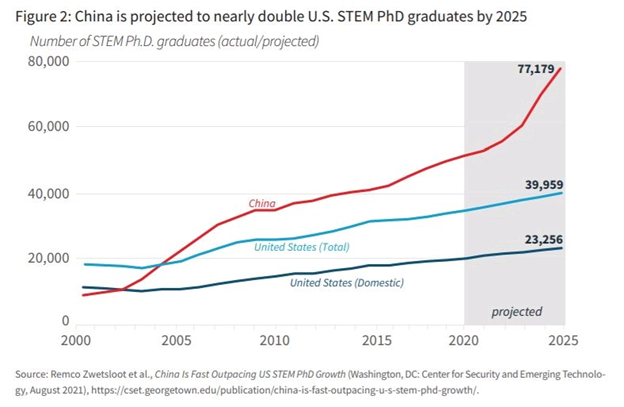
Fonte: Remco Zwetsloot et al., Center for Security and Emerging Technology, agosto de 2021
Essa concentração de talento, como é de se esperar, transborda para a pesquisa: em volume, a China já publica mais artigos científicos sobre IA do que os Estados Unidos. Quando olhamos para o impacto (medido pelo número de citações), os EUA ainda mantêm uma vantagem, mas essa diferença diminui a olhos vistos, e em várias áreas específicas, é a China quem já dita a agenda.
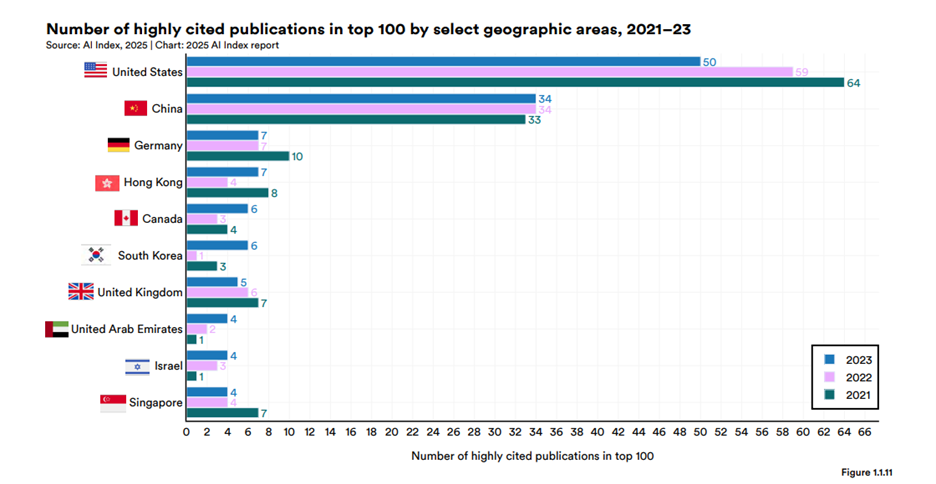
Fonte: Artificial Intelligence Index Report 2025
Na prática, o resultado é um ecossistema open source bastante rico, que desafia o velho estereótipo de que a China “só copia”. Empresas como Alibaba, Baidu e a própria DeepSeek tornaram-se contribuidoras essenciais para a comunidade global, lançando modelos, ferramentas e datasets de ponta que aceleram a inovação para todos. É dessa combinação de talento, pesquisa e contribuição prática que surge um ambiente propício à inovação em IA — mesmo diante de desafios externos, como as restrições ao acesso à chips de alta performance fabricados por companhias americanas, como a Nvidia.
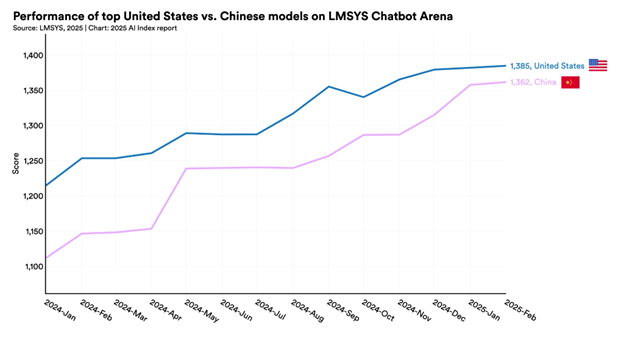
Fonte: Artificial Intelligence Index Report 2025
A diversidade cultural sempre foi um fator crucial no desenvolvimento tecnológico. Ela não influencia apenas como solucionamos problemas, mas a própria natureza dos desafios que escolhemos enfrentar. Um grande exemplo vem dos jogos de tabuleiro: basta comparar o Xadrez com o Go, o jogo milenar inventado na China. Quando Garry Kasparov foi derrotado pelo DeepBlue em 1997, o feito foi notável e amplamente comemorado. No entanto, muitos especialistas logo ponderaram que o verdadeiro teste seria outro: derrotar um humano em um jogo com regras muito mais simples, mas de complexidade exponencial, como o Go.
A expectativa da comunidade científica era que a máquina demoraria, no mínimo, um século para esse feito, e a razão era simples: o Xadrez, apesar de complexo, podia ser “vencido” na base da “força bruta” computacional. No Go, essa abordagem era inútil, já que o número de jogadas possíveis supera o de átomos no universo. Era preciso uma abordagem radicalmente nova, algo mais próximo da intuição humana.
E ela veio muito antes do esperado! Em 2016, o AlphaGo, desenvolvido pela DeepMind, chocou o mundo (principalmente os países asiáticos) ao vencer o campeão sul-coreano Lee Sedol. O ponto-chave é que sua arquitetura era baseada em redes neurais profundas — o mesmo pilar tecnológico que, de forma similar, sustenta os grandes modelos de linguagem que usamos hoje.

Fonte: Youtube
E é agora que a discussão converge: entra em cena a DeepSeek, a companhia chinesa que já deu o que falar no início deste ano. Seu mais novo modelo, o DeepSeek OCR, apesar de estar recebendo destaque (com todo o mérito) por seu ganho de eficiência, representa um marco muito mais profundo no desenvolvimento da IA.
O intuito não é entrar no aspecto técnico, mas se você está acompanhando bem até aqui, já entendeu a relevância dos tokenizadores e como eles geram vantagens desproporcionais para certas línguas, como o inglês. A abordagem do novo modelo é radical: ele simplesmente remove os tokenizadores tradicionais do processo, tratando o texto como imagens (ainda que sejam imagens de texto) e não como uma sequência de tokens.

Fonte: X
Ver esse novo lançamento da DeepSeek me fez lembrar de duas coisas. A primeira é que tive a oportunidade de fazer uma apresentação sobre o DeepSeek ao lado do João Piccioni no início do ano, durante o BTG Summit. Naquela ocasião, deixamos claro que a reação do mercado havia sido exagerada e que a companhia chinesa continuaria gerando inovações relevantes.

A segunda foi uma entrevista de Yann LeCun, Chief Scientist da FAIR (Meta), no podcast de Lex Friedman há cerca de um ano. Nela, ele defendia a necessidade de novas abordagens para o desenvolvimento da IA, argumentando que o futuro não estaria no simples aumento de escala das LLMs, mas sim no desenvolvimento dos “modelos de mundo” (World Models). Na sua visão, era preciso uma ruptura na forma como a IA estava sendo desenvolvida.

Fonte: Youtube
A minha hipótese, portanto, é que o lançamento do DeepSeek OCR marca o início de uma nova leva de modelos: mais democráticos (ao contornar os vieses de linguagem), fundamentalmente multimodais e, claro, drasticamente mais eficientes. Essa eficiência vem de uma capacidade de compressão de informação tão absurda que torna o custo de processamento muito menor.
Olhar para trás e ver onde já chegamos é surreal. Mas, acredite, estamos apenas começando!
Abraços,
Pedro Carvalho